最近Cursor新模型套壳Kimi的新闻,沸沸扬扬。
也正因此,对Kimi的赞美之声,也络绎不绝——毕竟是前一代vibe coding的王者“认证”盖章了。
Kimi、GLM、Minimax,目前被称为国产开源大模型的“御三家”。最近后两者靠着上市和卖Code Plan风头更劲,但Kimi靠着Cursor的“致敬”,也算扳回一城。
甚至因为最近的几篇论文,让许多玩家对Kimi更为高看了。
为什么Cursor选择Kimi“套壳”?除了Kimi K2.5发布的更早且开源之外,“多模态”我觉得是不能忽略的一个特性。
是的,国内的开源大模型虽然能力越来越强,但大多局限在文字上,原生多模态的极少,Kimi K2.5算是比较早,且完成度比较高的。
多模态有什么意义?
举个最近遇到的例子。
看到广发基金的一张表格,统计了一项功能的表现。想着基于数据进一步统计,那就需要将表格转换成Excel。
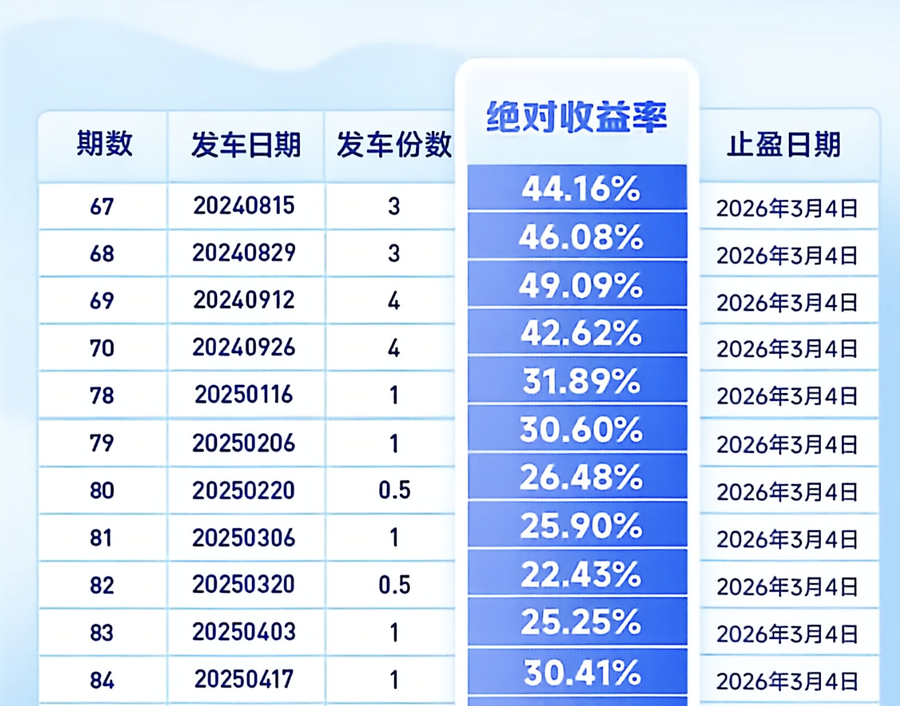
我是扫描全能王的付费用户,所以起手就是用这个APP,他家也以对Word、Excel转换而闻名。很可惜,失败了。上表因为“绝对收益率”被特别放大,所以扫描全能王转换失败,绝对收益率单独一块,止盈日期一块,前三列一块,显然不可用。

这时候,支持多模态的大模型就好用了。无论是Gemini 3.0 Flash还是Kimi K2.5,都能轻松将其识别,并根据我的要求变成Markdown表格。当然,你也可以要求变成CSV,那都是常规操作。
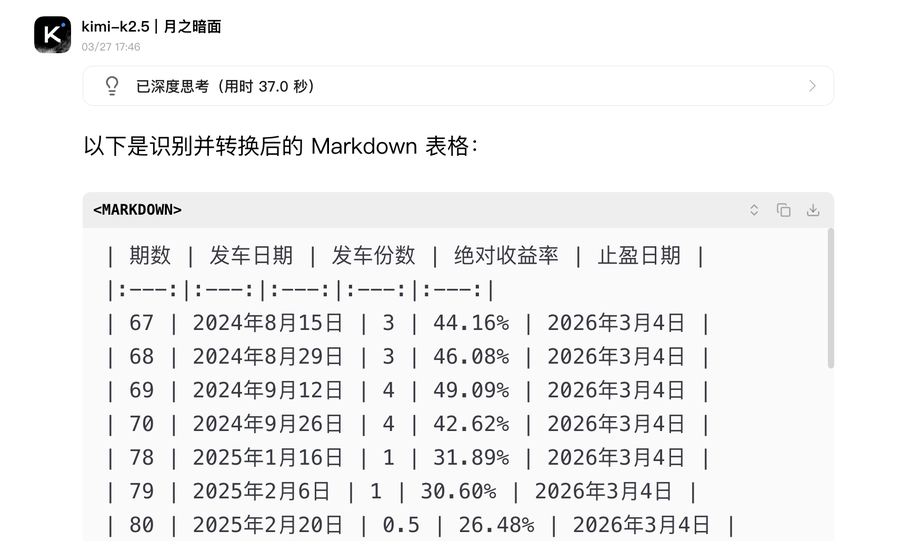
但这个活,用GLM或者Minimax的主力模型,就做不到了。
为什么飞书表格中内置Kimi K2.5,甚至成为许多人票据识别的首选大模型,也正是这个原因。
对于Cursor而言,由于长期内置的是Claude、GPT、Gemini这样的海外御三家,清一色都是原生多模态,所以许多程序员尤其是前端程序员,早就喜欢了开发前端出错,直接截图和大模型交互的体验——在这样的习惯下,Cursor自家模型要是不支持多模态,就是悲剧了。从这个角度,Kimi K2.5似乎都是当时开源界“没有选择的选择了”。
最后,说两个题外话:
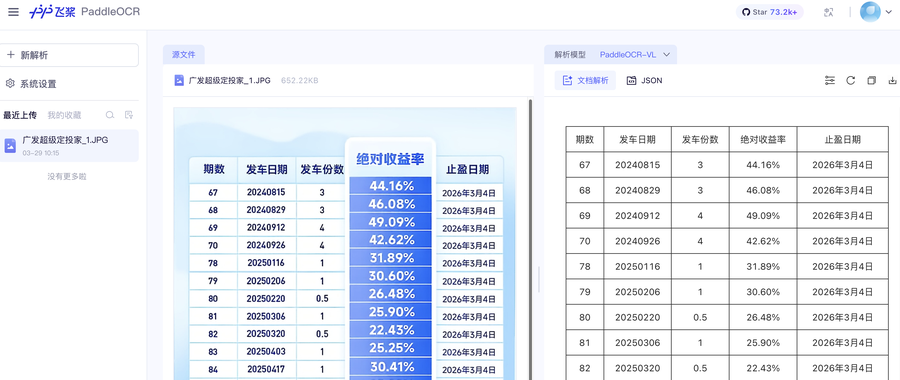
❶ 上面广发的那个表格,用百度的PaddleOCR-VL,也是轻松识别。虽然百度在国产大模型领域存在感越来越弱,但是在长期坚持的OCR领域,还是有独到之处。目前似乎去官网就能免费转换,额度不祥,但偶尔救急的话,还是相当可用。
❷ Deepseek 当前主力模型 V3.2 依然是一个文字大模型,不支持多模态。所以每次看到一些让Deepseek看走势图的分析师报告或者民间测评,大体就可以直接pass,作者显然连多模态是什么都没搞明白。