刷Openrouter,发现上线了一个名为Qwen 3.6 Flash的模型。
Qwen家的模型,一向是档位最细致的,Max、Plus、Turbo、Flash,至少四档。
不过Qwen 3.6系列,之前只看到Plus和Max,Flash是什么东西?翻了下官方微信号,也没看到发布介绍。
后来高人指点,才知道所谓的Qwen 3.6 Flash就是下图的Qwen3.6-35B-A3B。

不得不说,Qwen家的模型,不仅是多到眼花缭乱,而且模型名称马甲也太多。打开这篇推文仔细看才会发现,Qwen3.6-35B-A3B是尺寸角度的名称,但在阿里云百炼、Openrouter上线时,采用的又是之前的大中小杯的Flash产品型号,真是有些错乱。
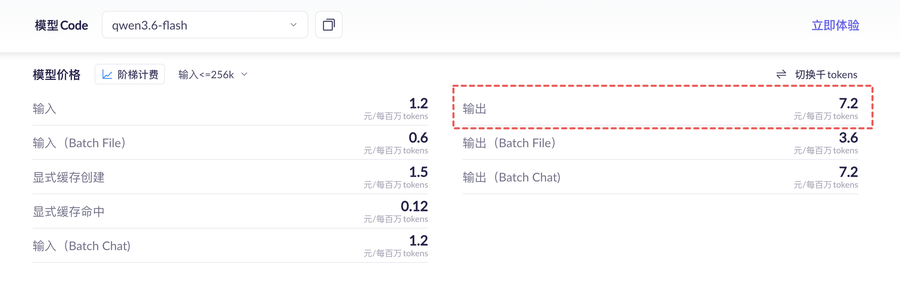
在百炼上刚看到Qwen 3.6 Flash的定价,我是有些迷惘的。怎么Flash也能定价到百万token输出7.2元了?
虽然我知道,Qwen从3.6系列开始普遍有一个定价的上涨,尤其是最高端的Qwen 3.6 Max版本,百万token输出更达到了54元的价格。但我依然对Flash的价格有些惊讶。毕竟相当能打的国产御三家的MiniMax M2.7的百万token输出也就是8.4元而已。
但后来突然想明白了,Qwen 3.6已经是一个多模态的模型,不能简单的去和纯文本模型对比价格,至少应该是和Gemini 3.0 flash这种多模态的版本去对比,后者的百万token的输出价格是3美元,即使是后来发布的Gemini 3.1 Flash Lite这个相对平价的版本也要1.5美元。
更何况在国产模型中,支持多模态的就不多,Kimi是一个,但是只有顶级的K2.6系列,并没有次一级的低价快速模型;小米Mimo的V2.5算是多模态,速度也不错,但百万token输出要14元。
在一些特定的场合,有一个快速多模态模型,还是很有用。
给两个我觉得有用的场景。
比如给一张照片,让大模型写小学生作文。
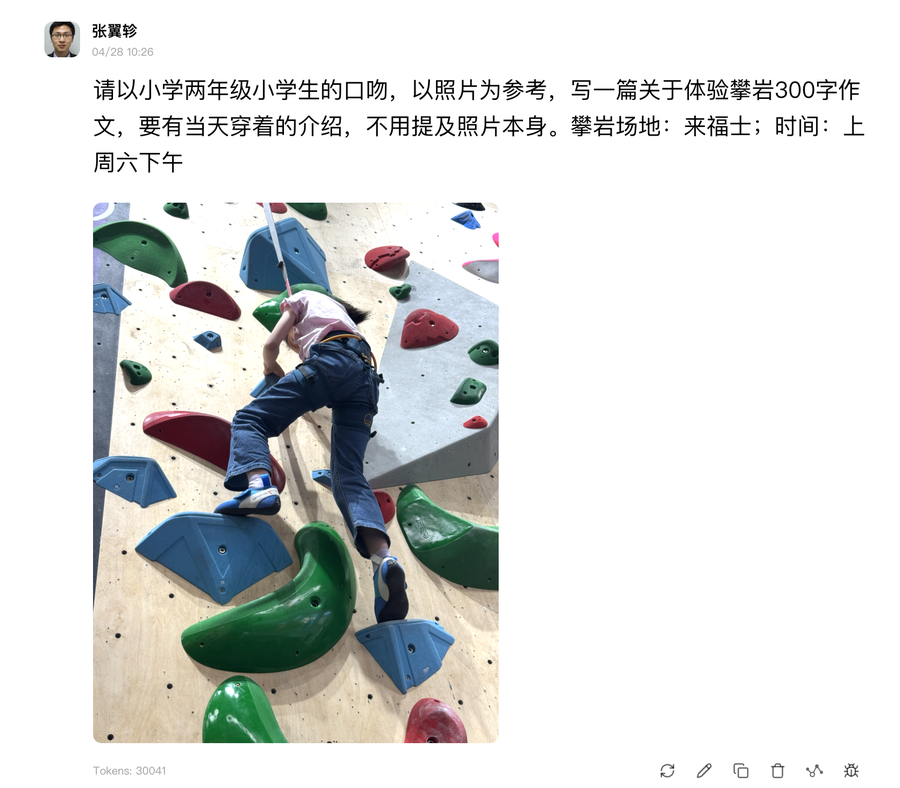
写出来的作文,还似模似样,类似踩在蓝色块状支撑,当天的着装等细节,也没错。每分钟token输出192个。

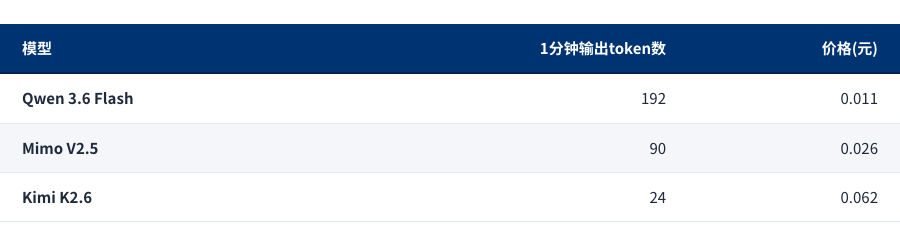
总花费0.011元,1分钱出头,还是挺有性价比。下表是我同样任务和Mimo V2.5还有Kimi K2.6的对比,输出token速度和价格仅代表我测试的那次,仅供参考。
再来一个场景,发票识别。
其实发票识别是OCR中很常见的场景,早在没大模型时代,就有很多AI接口了,不过也不便宜。
我记得自打飞书接入了多模态的Kimi K2.5后,网上就是一堆介绍用飞书内置的K2.5来白嫖识别发票的教程。
K2.5很好,就是太慢。我找了一张给娃买奶片的发票截图成图片测试了一下Qwen 3.6 Flash。
识别效果还是不错,0.0133元,最关键是速度很快,1分钟输出token可以达到245个。
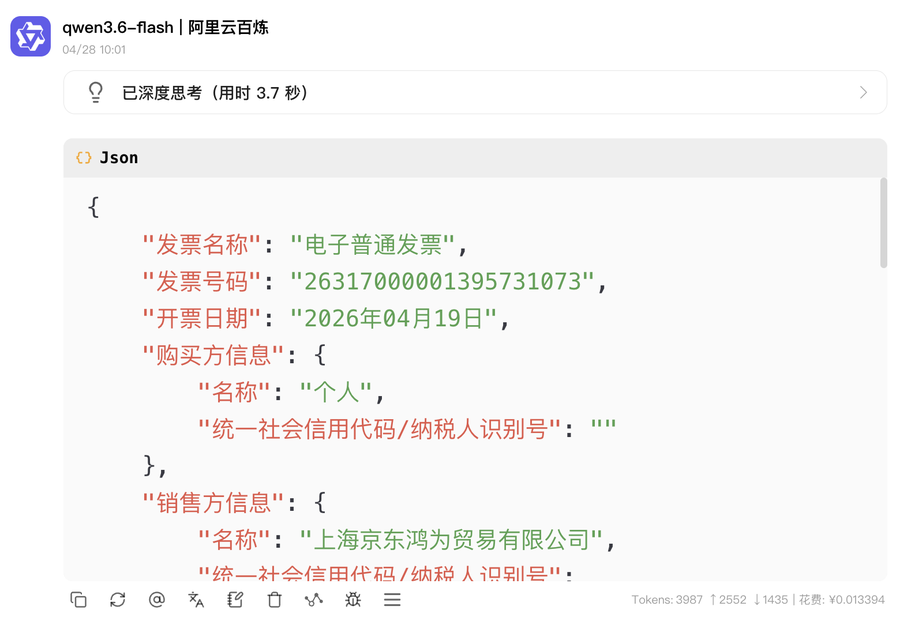
其实发票识别很成熟,包括百度PaddleOCR或者MinerU都有方案,不是多模态大模型专属的领域。
但多模态的好处是,如果有一些是自己定制的表格格式,用多模态大模型抽取,应该就要容易许多。尤其不是长期固定格式,而是时不时有变化的,多模态大模型更适应。
如今有Qwen 3.6 Flash和Mimo V2.5这两个速度都够快的模型,在国产多模态上,可用性就非常强了。