Deepseek V4发布了。
Deepseek V4 Pro又限时降价了。原本Deepseek V4 Pro的性能只是与其他国产大模型相若,缺乏惊喜,但一旦百万token的输出价格从24元腰斩再腰斩到6元,那就有点香了。虽然这次说是限时折扣,到5月5日,似乎只是让大家五一长假多多体验。但我总觉得,这似乎是一个“价格预告”,提前剧透下半年昇腾950批量上市之后,Deepseek V4 Pro的“大幅降价”能有多狠。
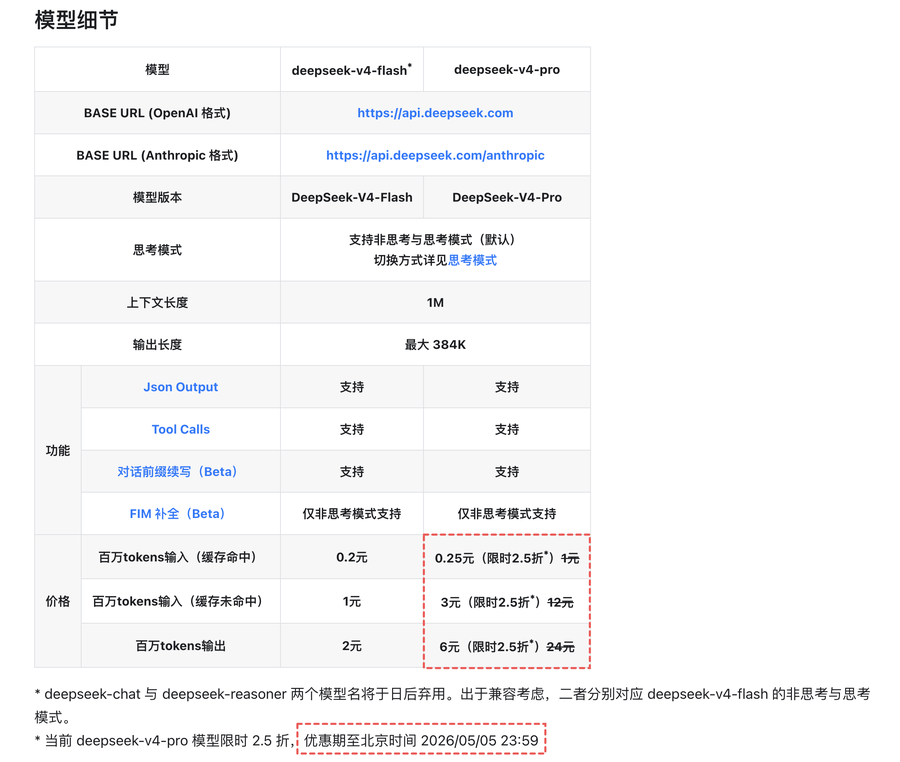
当然,本文的主角不是Deepseek V4 Pro,而是次级模型的Deepseek V4 Flash。
我一直相信,只有单个顶级模型的产品线,是不完整的。毕竟我们生活中许多的场景,需要的不是最顶级的智能,而是低价、快速。
比如沉浸式翻译。
这是我非常喜欢的Chrome插件,相比Chrome内置的翻译会将页面从全英文变成全中文,沉浸式翻译提供的是逐段插入中文,形成中英文对照的呈现(见下图),无论是学英语,还是对校原文,都是极好。

翻译这活,只是浏览网页,不需要太强的智能,用顶级模型,就有点高射炮打蚊子了。相反,如果希望快速阅读,反应速度反而是最重要的。
此前,我始终觉得沉浸式翻译最佳模型搭档是谷歌的Gemini 3.1 Flash Lite,这是在Gemini 3.0 Flash基础上特调的一个模型,有更低的价格(百万token输出1.5美元,Flash版再腰斩),同时搭配更快的速度,可以达到每秒100token的输出速度。翻译网页看,几乎无需什么等待。下图是Openrouter的模型对比。
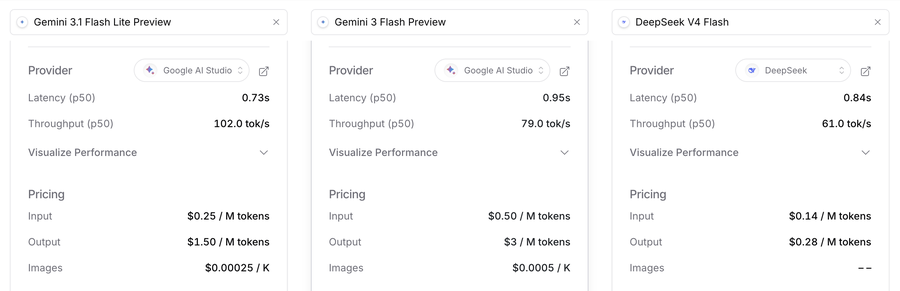
但Deepseek V4 Flash出来后,就都不一样了。
Deepseek V4 Flash的速度,当然还不能和Gemini 3.1 Flash Lite拼,但每秒60token的速度,比当年Deepseek V3.2是上一个台阶了,在沉浸式翻译的问题上,已经处于可以接受了——毕竟沉浸式翻译是逐段并发翻译,首字反应速度有时候甚至更重要。这点上,Deepseek V4 Flash介于Gemini 的Flash和Flash Lite版本之间。
但别忘了,Deepseek V4 Flash的单价,只有Gemini 3.1 Flash Lite的五分之一,Gemini 3.0 Flash的十分之一,在速度相若的前提下,性价比就极高了。
更何况,作为刚出的模型,在智能能力上,也是更为能打。

在低价高速国产模型上,Deepseek V4 Flash卡在了一个极好的生态位上。
在此之前,并非没有同类,但往往都处于上一代的版本,比如小米的Mimo已经到了V2.5,但是Flash快速模型还停留在V2.0;比如智谱的GLM已经到了5.1,但是Flash快速模型还停留在4.7,而且输出价格上相比Deepseek V4 Flash还没优势。
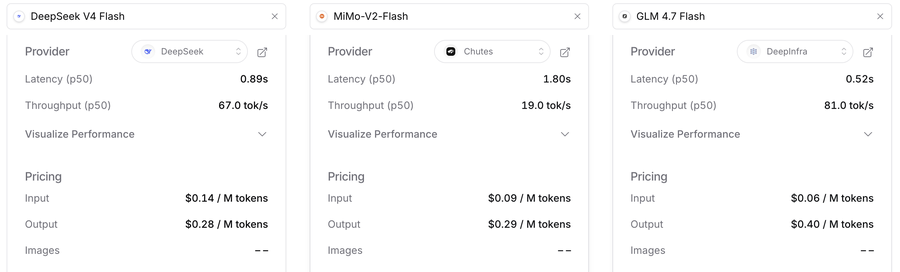
所以,至少就我而言,当下Deepseek V4 Flash是沉浸式翻译这样需要低价快速应用的绝配,反应足够灵敏,几乎不用等待。
最好的工具,大概就是这样——你用着用着,就忘了它的存在。