DeepSeek-V4 预览版终于发布了,在2026年4月24日的中午。
不久之前,英伟达的黄仁勋在Dwarkesh播客的那期节目Jensen Huang – TPU competition, why we should sell chips to China, & Nvidia’s supply chain moat上说:
DeepSeek 首次在华为上发布的那一天,对我们国家来说将是一个糟糕的结果。(DeepSeek is not an inconsequential advance. The day that DeepSeek comes out on Huawei first, that is a horrible outcome for our nation.)

当然,从4月25日美股的交易来看,暂时对英伟达,算不上horrible,股价大涨4.32%,逼近去年10月末的高点。
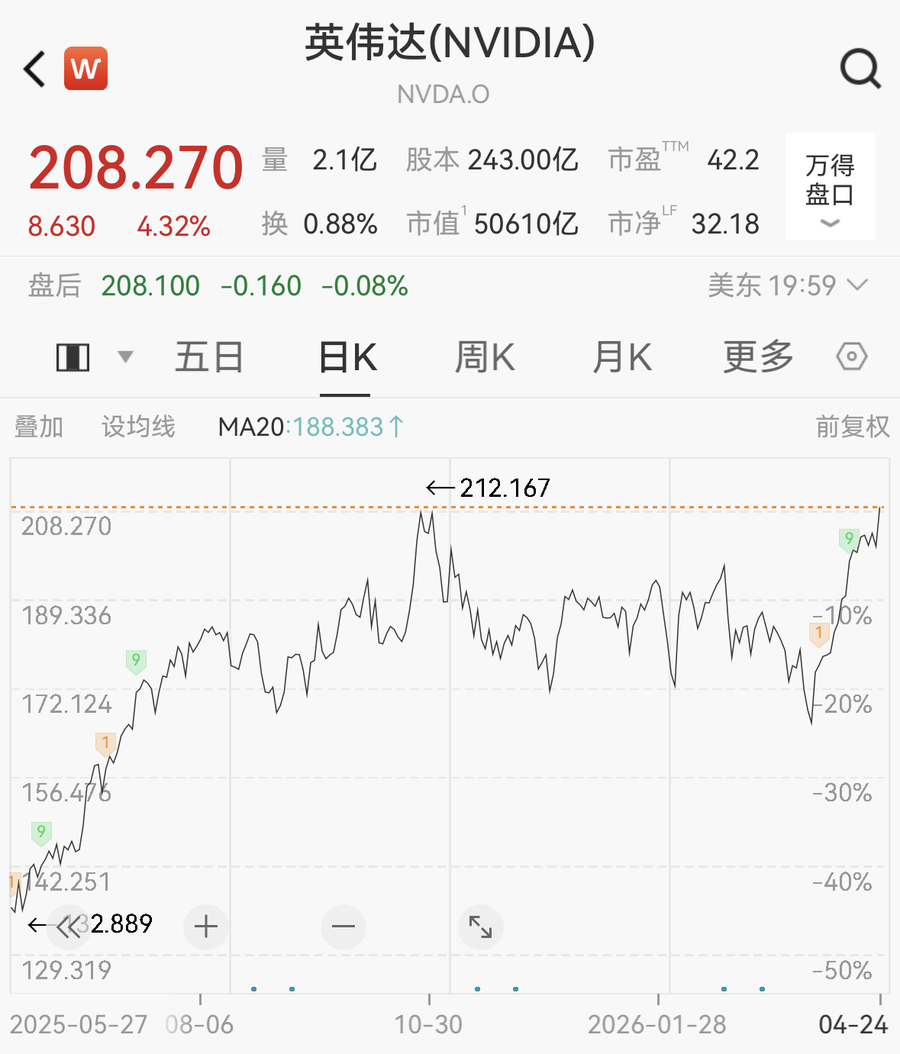
或许,包括GLM 5.1、Minimax M2.7、Kimi K2.6在内的一批中国模型,已经带来了太多类似的跑分结果,Deepseek V4并不如昔日的Deepseek R1能给我们一些“aha moment”的震撼,以至于英伟达的股民,更愿意顺从纳斯达克100一路向上的趋势,挑战新高。
但老黄的“horrible outcome”,显然不能视为简单的危言耸听,只不过需要时间的发酵。
这里就作为一个普通大模型用户,来聊聊Deepseek何时可能带来“horrible outcome”——当然,对于中国国产芯片的相关股民,可能就是一个“harvest time”。
Deepseek开始商业化
对于Deepseek,我是极有感情的。
我查了一下我的Deepseek API平台注册时间,是2024年7月19日。那时候,还只有Deepseek 2.5,R1的名声大噪是差不多半年后的事情。

在那个时代,Deepseek就是以“价格屠夫”而闻名的,当时被视为创新,如今近乎标配的全局缓存,从下图可以看到发布时间还早于Deepseek V2.5。
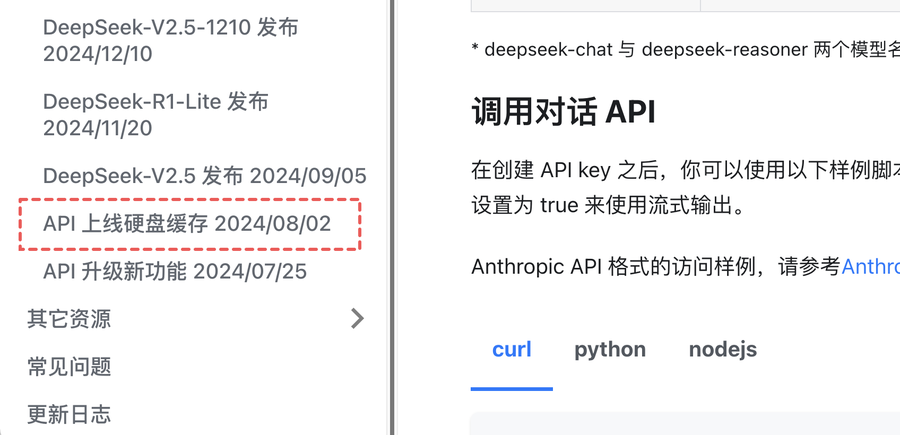
从那个时代开始,Deepseek的骨子里,就像是一个研究大模型的学术机构,兴趣在于探索大模型的疆界。这种学术味,一个最大的特点就是,“工业化”程度是不够的,始终走单一级别模型,没有模型阶梯。
如果你用过海外御三家的模型,能明显感觉到他们有着清晰的模型阶梯,至少两级。比如谷歌主力模型是Gemini 3.1 Pro,但也有Gemini 3.0 Flash辅助;OpenAI是在主力模型之下,有名为Mini的模型,之上后来又加了Pro,变成了三档;Claude目前则是Opus、Sonnet和Haiku。
不是所有的任务都需要最强力的模型。而且有些模型需要的只是简单快速。这时候入门级模型就能以更低的价格更快的速度提供够用的体验。
这其实在全球算力紧张的背景下,可以避免模型能力的“滥用”。如果你观察Claude Code的Agent工作,有时候就能观察到他自主降级使用Haiku完成一些基本的工作;Gemini Cli也是如此,大量基础工作让Gemini 3.0 Flash完成,高级活才交给Gemini 3.1 Pro。
但在模型分档问题上,国产模型或许因为弯道超车的需求,往往是比较忽视的——唯一的例外,或许是Qwen,从Max、Plus到Turbo,再加一些小模型,尺寸多到眼花缭乱,这也是全球大模型用户对Qwen一直交口称赞的地方,甚至连当年技惊四座的Deepseek R1推出时,也有基于Qwen的蒸馏小模型版。
下表是我做的一个统计,可以看到人称“国产御三家”的Kimi、智谱和Minimax,在次级模型上,要么没发力,要么很久没更新,这样的产品线,在Agent时代,其实会带来极大的算力浪费。
但这次,一向只有单一档次的Deepseek,反而是有了Pro和Flash两档模型,性能和价格,都兼顾了。
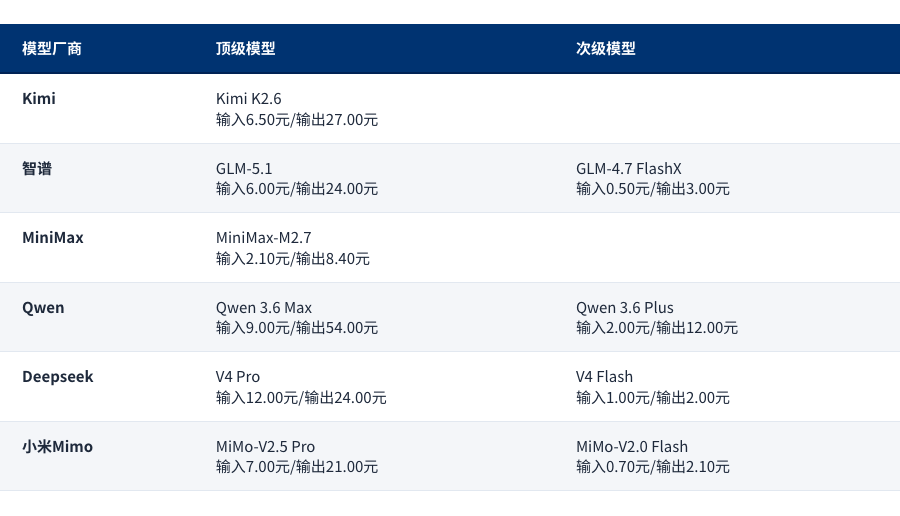
注:均为缓存未命中,且短上下文起始价格
最近张小珺《独家对话罗福莉:AI范式已然巨变!》有一个细节非常有趣,罗福莉在用上Openclaw的第一天,全程使用Claude 4.6 Opus,花费将近1000美元。
问题是,这个用法有几个人能承受?
别说Claude 4.6 Opus这样的顶级模型,哪怕是国产御三家的模型,如果不走Coding Plan,许多API付费用户都感觉用不起了。
如果相信Agent未来会越来越重要,那么多个模型的搭配,也会越来越重要。在这个问题上,Deepseek V4显然做了迥异于国产御三家的一个选择。
联系近期Deepseek以200亿美元估值谋求融资3亿美元的传闻,似乎Deepseek正在走出那个纯学术化的过去,更开始像一家企业去思考。
多档模型,考虑的是用户的实际需求(尤其是非编程用户和Agent的性价比需求),融资或许也会考虑员工薪酬、变现等实在的需求,毕竟过去一年多,从Deepseek出走的核心员工并不少。
作为非上市企业的Deepseek
当然,Deepseek最让黄仁勋忌惮的,或许依然是那个私人非上市企业的身份,这意味着Deepseek可以随心所欲的做一些“难而正确的事情”——是的,我说的是与国产芯片的适配。
虽然目前在Deepseek V4是否用国产芯片训练模型上没有定论,但推理使用时用国产芯片,却是板上钉钉的。
这次Deepseek V4发布时,最让中国国产芯片股东们兴奋的,是一行小字:

下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。
“大幅下调”是什么概念?
Deepseek,作为“价格屠夫”,给我们示范。
2025年8月21日,Deepseek V3.1发布时,大家觉得模型性能也就这样,百万token输入4元/输出12元的价格也有点小贵。
但不过是一个多月后的9月29日,DeepSeek-V3.2-Exp的发布,把百万token的价格打到了2元输入,3元输出,一下子就真香了!

当下,Deepseek V4 Pro的定价和性能,或许让人觉得还有些“路人”,但若价格腰斩甚至更多,那时Deepseek V4的竞争力或许才会凸显。
更重要的是,国产芯片的竞争力会进一步显现。
周五(4月25日),中国A股全指半导体指数大涨1.65%。“国产替代”,是中国半导体股过去几年能够持续上涨的根本逻辑,而Deepseek从去年3.1开始,也为这一逻辑在不断添砖加瓦。
最著名的,当属Deepseek V3.1发布时,Deepseek微信小编在评论区的那句留言:

次日(8月22日),中国A股全指半导体指数暴涨8.26%,而同日中证A股仅上涨1.65%,足可见市场对这一表态的亢奋。
我统计了一下,目前A股跟踪各类芯片股的ETF规模有1781.61亿元,而以芯片股为核心的科创50ETF规模也有1355.32亿元。Deepseek传闻中的3亿美元融资,不过20亿人民币而已。相比上面两类ETF合计3000亿元+的规模,不到1%。
作为科创50ETF的持有人,你问我是否愿意拿出不到1%的净值入股Deepseek,我是双手双脚赞成的。都不用在乎Deepseek本身的投资是否能赚钱,光光是让国产芯片逻辑继续走下去,就值了。
相信有我这样想法的持有人,应该不在少数。
是的,国产芯片要崛起,不仅需要芯片业的努力,也要大模型产业的配合。
正如古龙常言,真正最了解你的,往往是你的敌人。黄仁勋之所以点名Deepseek,也正是知道愿意在国产化道路上花最大苦功夫的,必然是Deepseek。
毕竟,对于大模型业务已经在上市公司框架下的玩家,有太多现实的牵绊,而Deepseek反而可以更纯粹。
在大模型这样类似学术研究的领域,纯粹是一种可怕的力量。
所以,黄仁勋的“horrible outcome”何时到来?
答案或许藏在他自己的话里。他没有说“if”,他说的是“the day that”。不是会不会发生,而是什么时候发生。
有意思的是,在同一段对话中,黄仁勋还说了一句很少被引用的话:“Because they’re limited in compute, they also come up with extremely smart algorithms.”——正因为算力受限,他们反而发展出更聪明的算法。
这几乎就是Deepseek的注脚。
资源的匮乏没有成为枷锁,反而成了磨刀石。从R1时代的推理、V3.2时代的“价格屠夫”路线,乃至V4对国产芯片推理的适配,都在印证同一个逻辑:当纯粹的研究热情遇上真实的约束条件,解题路径往往比资源充裕时更具创造性。
下半年,昇腾950超节点批量上市。届时Deepseek V4 Pro的价格大幅下调,而全球的开发者用脚投票。那或许就是“the day”的开始——不是惊天动地的一天,而是许多个寻常日子的累积,直到某天回头看,才发现局面已经不可逆转。
对英伟达的股东而言,这大概不算好消息。但对于科创50和半导体ETF的持有人来说,这正是拭目以待的剧本。