五一期间,密集在Agent模式下,体验Deepseek V4,尤其是便宜的Deepseek V4 Flash。
一边用,一边算价格,一边感叹:Deepseek V4的缓存读取价格,真是便宜到离谱。
经常调用大模型API的应该知道,大模型的定价,在百万token下,有三个核心定价:未命中缓存读入、命中缓存读入和输出。
在Agent时代,由于大模型要频繁调用工具,需要频繁将之前的上下文重新发给大模型,所以命中缓存读入的价格,对整体费用的影响极大——前段时间Cluade Code被大家吐槽的一点就是,悄悄在上下文“加料”,让许多用第三方模型搭配Cluade Code的玩家,遭遇缓存未命中,成本骤增的问题。
正因此,模型厂商如何定价命中缓存的价格折扣,对长期使用成本,影响不小。
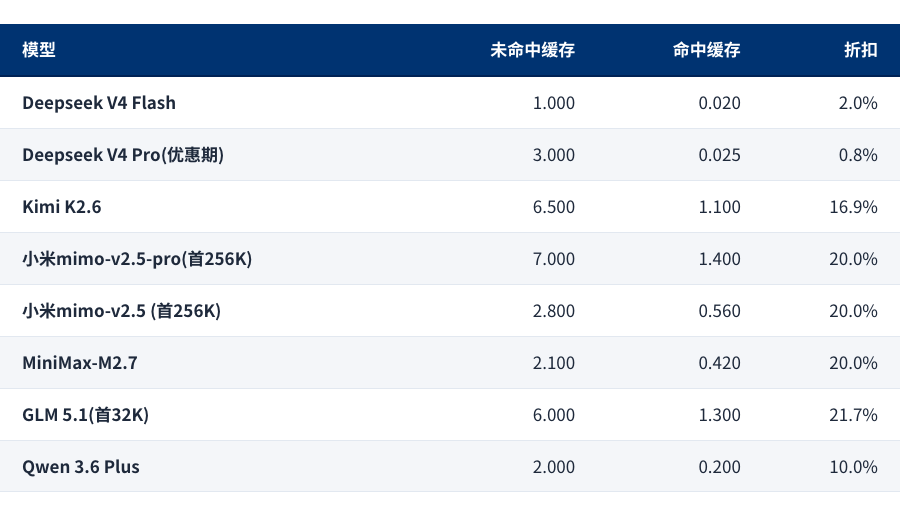
下图是我整理的几个国产厂商模型的读入价格对比,均为百万token的人民币报价。你会发现国产“御三家”,也就是Kimi、GLM和Minimax都是20%上下,小米Mimo也是,Qwen便宜不少,是10%。但这些折扣,和Deepseek V4放到一起,就黯然失色。Deepseek V4 Flash是2%,而Deepseek V4 Pro竟然只有0.8%,只要是命中缓存,价格便宜到离谱!!!
今次Deepseek V4的发布,许多人觉得模型中庸,没有惊喜。
惊喜,或许就藏在缓存价格中。
Deepseek的缓存价格,不是从来那么便宜的。
特地查了一下去年V3.2发布时,缓存的价格是未命中缓存的10%,算便宜,但没那么离谱。

显然,Deepseek V4的技术上,有足够的突破,把缓存读入的成本打下来。
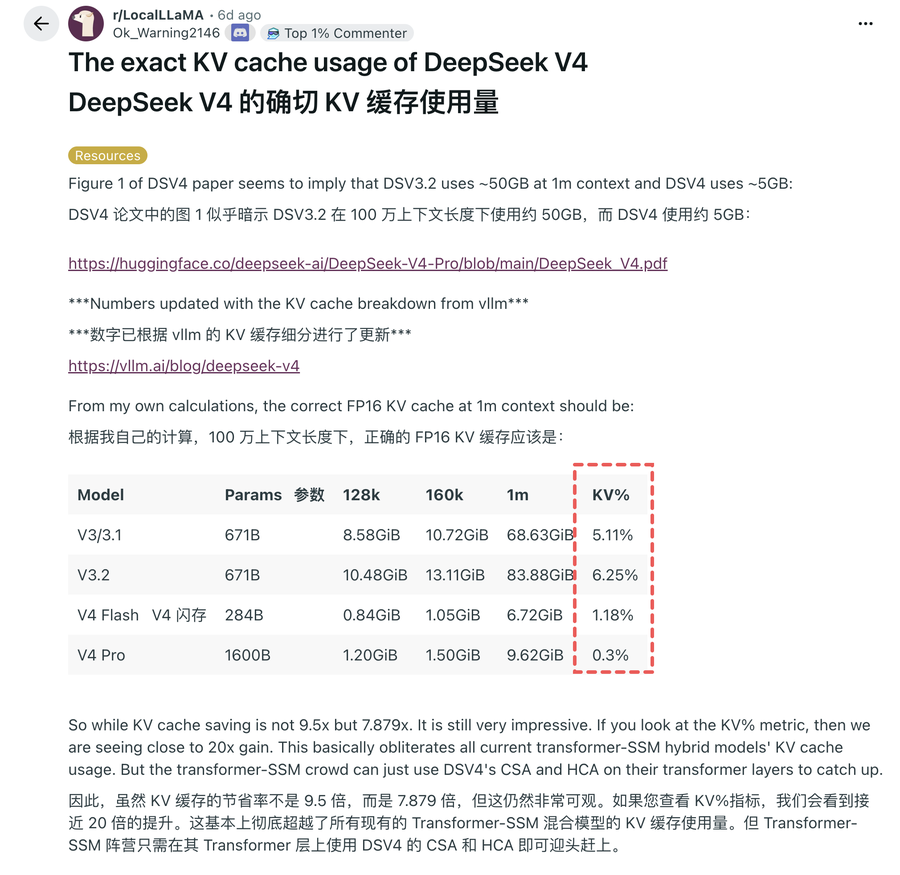
Reddit上有一篇帖子,对Deepseek几代模型的KV Cache做了一个分析,这或许是Deepseek V4缓存读入价格折扣巨大的原因——成本的确下降。
我只是大模型的普通用户,专业这块是不懂的,所以也只能看看Gemini Deepresearch的综述,它是如此概括:
在DeepSeek V4的架构下,处理被缓存的百万Token前缀,其在GPU算力核心上产生的实际浮点运算(FLOPs)趋近于零。供应商所需支出的成本,实际上仅剩下微小的PCIe传输能耗与硬盘折旧费。相较于传统GQA架构即使缓存也必须吃满HBM带宽的窘境,DeepSeek将I/O依赖转化为异步轻量操作。因此,向开发者收取$0.003625(仅为未命中成本的约0.83%)或Flash版本的$0.0028(2%),是在精准覆盖这层极薄的硬件传输成本后,依然具备商业毛利的必然结果。
那么这个技术优势如果未来被更多模型尤其是国产模型接纳,对整个硬件架构会有什么影响?
作为门外汉,依然是请Gemini 3.1 Pro的搜索和分析,仅供参考。
对国产算卡
国产芯片最大的痛点是显存带宽(HBM)和片间互联(类似 NVLink)不够强。V4 的 MLA 架构大幅压缩了 KV Cache 体积,在 attention 环节对 HBM 带宽的需求显著降低,这在一定程度上缓解了国产芯片的带宽劣势——虽然 FFN 和 MoE expert 调度等其他环节的带宽需求仍然存在。
据报道,DeepSeek V4 原生适配了华为 CANN 架构,在昇腾上的利用率从以往的 60% 左右提升到了 85% 以上。如果数据属实,这意味着在特定推理场景下,国产芯片与英伟达 A100/H100 的实际效能差距正在缩小。
对高端存储
HBM(高带宽显存)一直是 AI 芯片(如 NVIDIA H100/B200)最昂贵的组件。DeepSeek V4 大幅削减了 KV Cache 的体积,如果这一技术路线被广泛采用,对 HBM 容量和带宽的需求增速可能放缓。韩国(SK 海力士、三星)目前是 HBM 的绝对统治者。
换个角度看,KV Cache 从 HBM 向更低成本的存储层级迁移,或许会利好“大容量、通用型”的存储方案(SSD 和 DDR5 内存),国产存储厂商有机会从中受益。当然,HBM 的需求不只取决于 KV Cache,训练侧和其他推理环节仍是 HBM 的大户。
对光模块
DeepSeek V4 降低了单次推理对极致瞬时带宽的依赖,如果现有的 400G/800G 网络环境已能满足推理需求,那么向 1.6T 或 3.2T 超高速模块升级的紧迫感可能会被削弱。
另一方面,V4 采用的 Engram 架构将部分知识存放在 SSD 和内存中,推理时需要在“计算节点(GPU)”和“存储节点(SSD 阵列)”之间交换数据。这种计算与存储分离的架构(Disaggregated Architecture),反而可能创造新的机柜间光纤连接需求。
整体趋势或许是从追求“极速”转向更看重“极稳”与“高密度”。
是的,这些分析大多来自Gemini的搜索综述,我作为门外汉只能做粗线条的转述和判断,细节上一定有不够精确的地方。
但有一点我比较确定:当大家还在讨论Deepseek V4的跑分够不够惊艳时,它在架构层面对成本结构的重塑,或许才是更值得关注的变量。0.8%的缓存折扣不是营销噱头,背后是KV Cache体积实打实的压缩。这个变化如果沿着产业链往下传导——从HBM到存储,从光模块到算卡——影响不会小,只是需要时间显现。
标题里用了“尚待”两个字。坦率讲,多久能显现,我不知道。但价格信号往往是最诚实的,当缓存读入便宜到只剩零头的时候,硬件端的账迟早要重新算一遍。