刷新闻,看到某科技公司老总,“炫耀式”检讨,说一个月token消耗量只有20亿。
之前也听说过,微信中有一些AI重度用户群,以日消耗1亿token为入群门槛,甚至称之为“1亿token俱乐部”。
仔细想想,这事儿最有趣的地方大概在于,对于绝大多数男性,日消耗token数量,或许是仅次于精子含量的,第二个可以用亿计算行为的个人“特质”了。
但这种攀比,总感觉有点“登”味。
日消耗1亿token多吗?
在Agent盛行的年代,这个看上去很恐怖的数字,其实越发变得稀松平常。
打开我的Deepseek后台,随手看了下,5月4日放假在家,在Deepseek V4 Flash上消耗了5191万token。但我那天做了什么?我都不记得了,反正没做成什么惊天动地的大事。
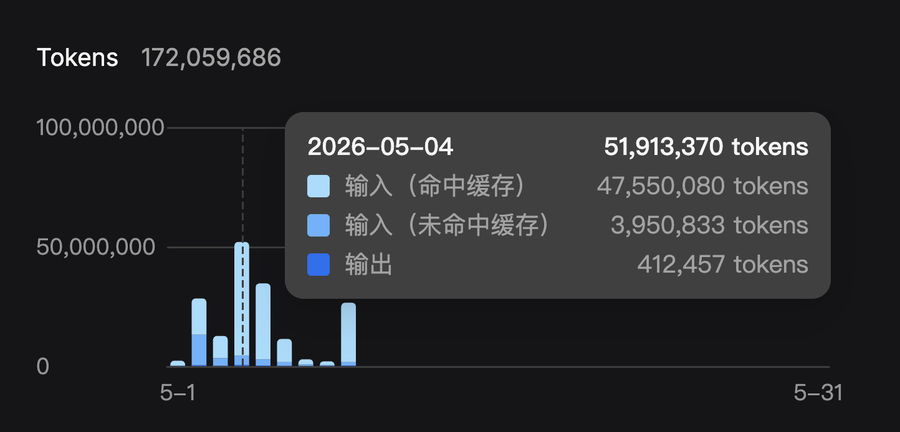
其实,Agent时代,当Agent需要频繁调用工具,并将工具的结果返回给大模型时,每一次都会将上下文的数据刷新一次。考虑到许多Agent载入系统提示词后的上下文就有1-2万token,再载入点什么内容,然后通过频繁工具调用,很轻松就能刷出几十倍甚至上百倍的token消耗量。
从我那天5191万token消耗中,命中缓存的读入是4755万,而未曾命中缓存的读入只有395万,就能看出绝大多数的token消耗,其实只是工具调用过程中的不断重复。如果看真正能体现产出的token量,就只有41万,少得很了。
所以,Agent时代,1天刷1亿token,技巧得法,易如反掌。含金量,大概和买个专门机器刷微信步数一样。
其实早有聪明者总结出技巧,只要当大模型读取一个很长的文档,然后比如逐行翻译写入之类,能频繁调用工具的工作,很快就能刷出天量token消耗了。
为什么会有这样的技巧研究?
因为有公司会将token消耗去排行,甚至作为员工“All in AI”的新KPI——一种用账单证明态度的管理艺术。最著名的,自然是Meta的单月2810亿token的消耗。

然而,正如用每天代码行数去评价程序员是一种“外行”行为,只看token消耗,对专业人士而言,有的是作弊的手段。
始作俑者Meta,在消息泄露后就下线了这个排行,但这一文化,显然依然在全球的AI圈蔓延,至少在中国,挺火热。
但换一种角度想,当我们使用AI,真正重要的是过程还是结果?
当我们炫耀每天消耗多少token的时候,是否意味着除此以外,我们并没有什么成果拿出来炫耀?
历史上每一种“以消耗量论英雄”的KPI,最终都沦为笑话。咨询公司比谁的PPT页数多,互联网公司比谁的加班时长长,现在轮到比谁烧的token多了。
形式在变,那股“登”味,倒是一脉相承。