最近,一直在打磨用大模型跟踪股票账户表现这件事儿。
之前,写过《用Qwen 3.6 Flash复盘股票账户》,聊如何用多模态模型,将券商的逐日数据转换成统计软件可以分析的CSV文件。
后来,也写过《同花顺投资账本,好用,但仍有待提升》,表扬了这个软件的创新,但也指出了一些遗憾。
在我看来,对普通股民,同花顺的这个投资账本APP足够了,尤其是有多个股票账户的话。
但对我,还不够。
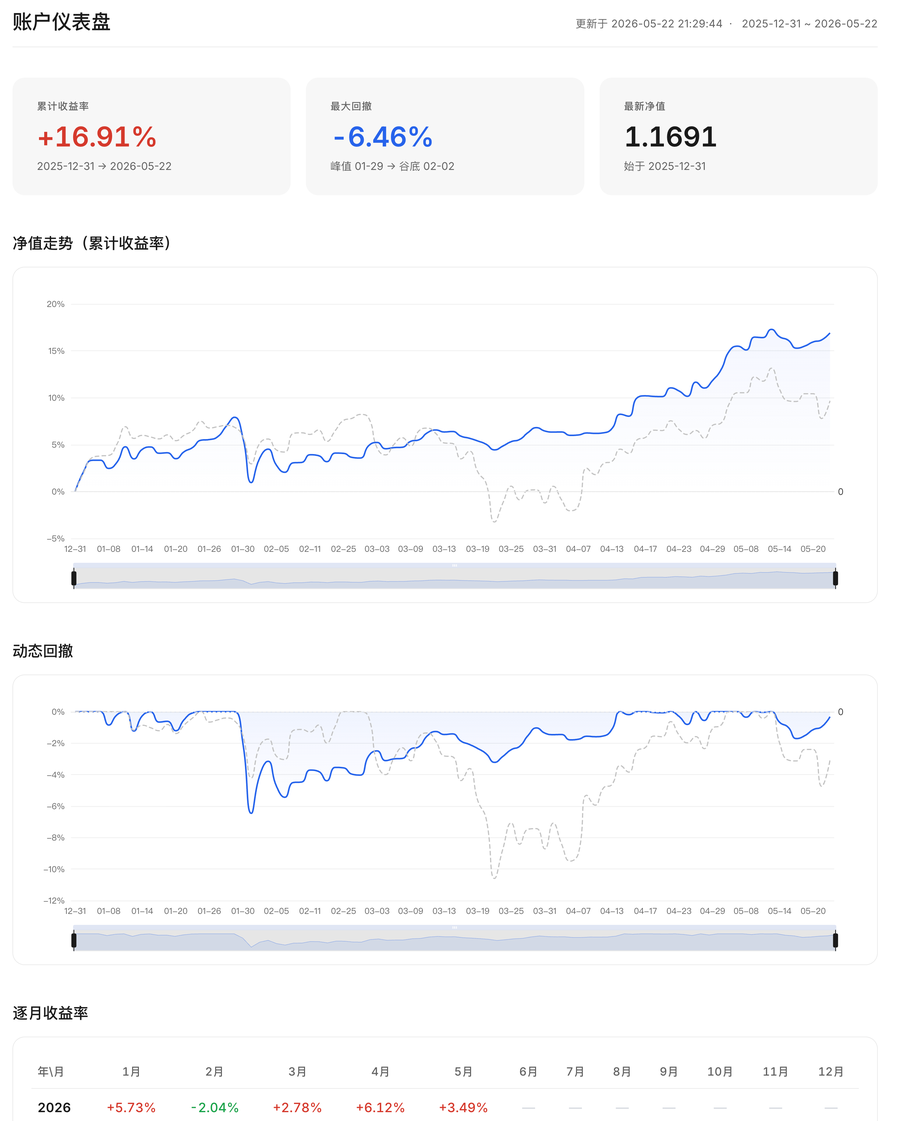
一个是之前提到的,只有最大回撤标记,而没有全程的回撤曲线,对于我这样对于回撤特别关注的人,少了最重要的一个信息;
另一个是作为对比的指数,虽然不少,但清一色是价格指数而不是全收益指数,这会显得超额更高,有“注水”。
所以,还是依靠AI,Vibe Coding,手搓了一套,目前的效果大体如下,包含了收益曲线、动态回撤曲线和月度收益三块。作为基准的指数,采用的是我最偏爱的中证A股全收益指数(灰色虚线)。
关于这个Dashboard,分享一下开发时的心得,对于希望自己手搓一套的,可以有些借鉴。
环节一:识别逐日收益
在最初,我是用大模型识别券商软件的逐日收益率数据,但是后面改成了当下的逐日收益金额数据。
之所以有这个转变,在于收益金额,是一个真实的数据,而收益率则是基于算法计算而来的,这里面就牵扯到资金流入流出干扰的算法,有不确定性因素。
收益值,就实实在在了。
环节二:资金进出手工登记
在我最初做大模型识别的时候,会将逐日收益金额截图和资金转入转出截图,一起交给大模型来识别,输出三列数据:日期、盈亏金额、资金进出。
但后来优化之下,把资金进出环节给剔除了。
主要是资金进出是低频事件,如果每次识别都要增加一列资金进出,里面几乎清一色0值,其实会浪费太多的输出token
所以我现在识别的提示词很简单:
你是一个专业的金融数据识别助手。请识别图中显示的股票软件“月度收益”日历数据。 规则:
- 首先识别图片顶部的年份和月份。
- 提取日历中所有具有红色或蓝色背景的日期。
- 红色背景代表正收益,蓝色背景代表负收益。
- 提取日期(日)和对应的收益金额(保留两位小数,如 +1.81 或 -0.10)。
- 将日期转换为 YYYY-MM-DD 格式。
- 以 CSV 格式输出,包含两列:日期,当日收益。
- 只返回 CSV 内容,不要有任何开场白、解释文字或计算过程。
我这个是基于自己券商软件的颜色表示,做了更严格的约束。你可以根据自己券商软件的截图微调。
在探索阶段,我是在CherryStudio中要求他导出CSV,但现在追求半自动化,就是写了个python脚本,用litellm库做接口,去调用阿里云百炼上的qwen3.6-flash模型,返回CSV之后,我会用python程序再给CSV加一列“资金流入”,数值全部标记为0,然后写入本地的CSV文件,并要求脚本按照YYYY-MM.CSV来命名,比如2026-05.CSV这样。
如果当月我有资金进出,我就会手动编辑,然后在“资金流入”这列增加资金进出的数字,流入是正值,流出则是负值。如果没有,这个文件就可以下一步交给下一个脚本使用。
环节三:维护底层数据
在最初的探索中,我已经有一个起始于2025年12月31日的数据文件,包含日期、当日盈利金额、当日资金流入、总金额、当日收益率和净值六列。
有了类似上面提到的2026-05.CSV后,我会用第二个脚本,去更新这个底层数据文件。因为我是pandas爱好者,所以底层是以parquet文件存储。
其中日期、当日盈利金额和资金流入,是上一个环节通过图像识别和手动更新输入的。
总金额,是基于上一日的总金额和当日盈利金额计算而来的。当然,在更新脚本中,我会允许基于券商软件给的最新总金额数据,去回溯之前每天的总金额数据。毕竟因为现代股票账户的总金额还包含场外基金尤其是货币基金等多类资产,其总金额往往在动态变动,所以我会在追求校对至最新总金额的前提下,做类似的回溯校准。
当日收益率,是以上一日的总金额和当日收益金额来计算,也就是假设当日流入或流出的资金,都是收盘后,对当日投资没有影响。这只是一种为了方便计算的假设,虽然实际中股票账户的资金是可以盘中流入盘中使用,但这样计算就过于麻烦了。
净值,类似基金净值,我是以2025年末为1,基于当日收益率来计算。也就是我采用的是时间加权,而不是资金加权,更多是方便绘图直接使用。
当然,我有一个单独的脚本,可以基于时间加权和资金加权,分别计算整个过程的收益率,但其实对我这样难得资金进出的人,意义有限,极少使用。
在更新完上述所有数据后,我会重新写入parquet文件作为底层数据,同时还会输出两个格式:
- CSV格式。这个主要是用来方便查看。因为parquet是pandas专用的格式,体积小,还能保留格式,但无法用文本软件查看;
- JS格式。JS格式,是JavaScript脚本,是为下一步给用HTML写的前端网页使用的。之所以没有使用常见的Json文件,是为了避免浏览器本地读取Json的障碍,不用单独启动一个本地服务器,直接打开HTML页面即可。
在输出JS格式的时候,我还加了一列中证A股全收益指数对应的数值,这是我个人对基准的偏好。这个指数的数据来源,网上有很多库和很多方法可以获得,这里我就不展开了。
环节四:HTML呈现数据
有了数据,用HTML呈现就比较简单了,随便用个什么AI编程软件或者Agent,告诉它需要哪些模块,就能编写了。
不过里面有些细节,要提醒:
- 我绘图是指定用百度的ECharts 5,你如果只是指定名称,有些大模型会设置错误的链接,所以不妨直接告诉它库是 https://cdn.jsdelivr.net/npm/echarts@5.6.0/dist/echarts.min.js
- 直接让它设计,可能出来的视觉效果比较丑,最好加以约束。比如我用的是HP风格,喜欢什么风格,可以去https://getdesign.md/ 浏览,寻找你喜欢的风格。找到之后复制对应的DESIGN.md文件,让大模型照着设计就好。
- 中国股民热爱以红色表示上涨,绿色表示下跌,这个信息要告诉大模型,不然有时候它们会采用美国的绿色上涨红色下跌。
其他的,也没什么值得注意的了。
毕竟,这只是一个很简单的需求,但能够自定义,的确能方便许多,可以呈现自己喜爱的数据,同时还可以根据需要不断增删改进,这也算是大模型时代的新体验了。