早上一起床,就看到了小米MiMo永久降价的公告。

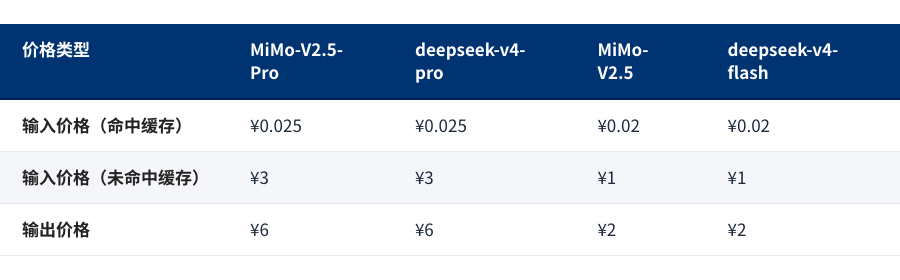
这次降价,一言以蔽之,就是对齐Deepseek V4。
下面这张比价图,是正是让Mimo-V2.5的多模态能力,识别两家官网后合成的。
很清晰可以看到,从Deepseek V4最赖以自豪的超低缓存命中输入价格到输出价格,全部是像素级的对标。
更重要的是,小米MiMo补全了此前Deepseek V4缺失的一项服务——Coding Plan。以最低配的39元,按照95%的命中缓存计算,使用低端的V2.5可以用5亿token,用高端的Pro模型,可以用接近2亿token。
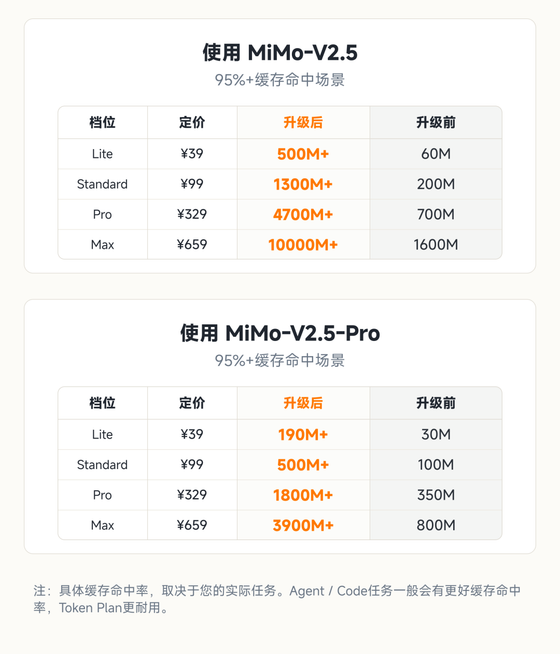
这个套餐定价,还是有点意思。
看了下我的Deepseek控制台,虽然Deepseek V4够便宜,但是本月的消费也有67.48元,而我消耗的token,不过是Deepseek V4 Pro不到5000万,Deepseek V4 Flash模型2.4亿而已。
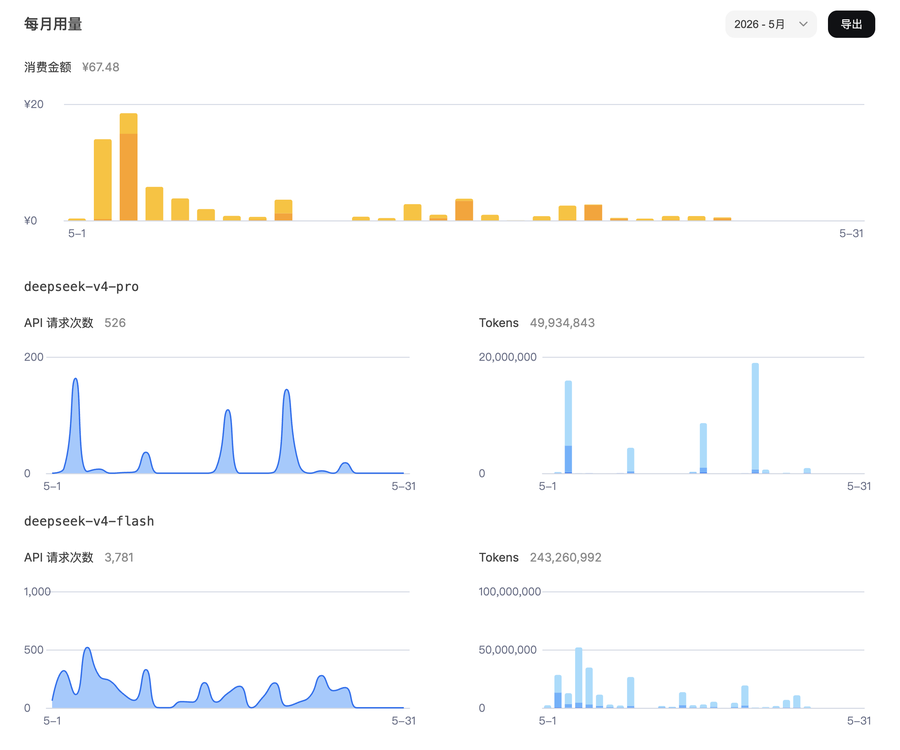
虽然模型的实际消耗价格,和输入还是输出有很大的关系,不过按照小米的Coding Plan,V2.5 Pro差不多是V2.5的三倍消耗来折算,我上面Deepseek V4上的消耗,差不多相当于Mimo V2.5模型4亿的消耗量,还在39元的套餐覆盖下,这么算,性价比就更高了。
之前写过好几篇Deepseek V4,最近也是最具有代表性的是《Deepseek V4对存储、光模块需求的打击尚待显现》,我的一个核心观点就是Deepseek V4基于技术上的改进,大大降低了模型的实际成本,尤其是缓存读入的价格,不但在Agent这样大量高频触及缓存的模型应用形态非常重要,而且由于Deepseek V4的架构更依赖普通的SSD硬盘,而不是昂贵的HBM内存,对整个中国的半导体产业是利好,可以降低对韩国高端存储的依赖。
曾经以为,Kimi作为和Deepseek一直有技术互动的厂家,可能是率先会跟进的。
没想到,竟然是小米MiMo,在它家这次的降价公告《MiMo-V2.5 系列调价公告丨 百万亿 Token 创造者激励计划收官》中,有这么一段非常核心的内容:
本次价格调整背后,离不开小米技术团队在推理系统上的持续优化。
我们基于 SGLang HiCache 完整支持 SWA(Sliding Window Attention),将 KV Cache 在 GPU 显存、CPU 内存、SSD 等多级存储之间的数据搬运量降低至优化前的近 1/7,并将可缓存 token 数量提升至优化前的近 5 倍,显著提升了缓存命中率和推理效率。
同时,我们通过优化专家并行方案、输入长度分桶策略等,进一步提升了集群输入吞吐能力,从而在保障服务质量的前提下持续降低单位 token 服务成本。
显然,小米MiMO此次的降价,是基于技术提升后成本下降的自然降价。
这才是相比为了获客的价格战更可怕的事情——如果依托工程师红利,我们可以通过技术优化来降低对算力、存储的需求,那么对美国领导韩国重度参与的半导体生态构成冲击,但显然利好中国的算力和入门级SSD硬盘。
当然,无论是Deepseek V4还是MiMo 2.5 Pro,在全球大模型生态下,只能说是第二档的模型,和Cluade Opus还有GPT 5.5还是有显著的差距,在最具生产力的代码前沿还有巨大的追赶空间。
但是,大模型的应用,并不只有代码。尤其是今年龙虾的热潮,证明了许多普通人也有Agent的需求,甚至是低价好用Agent的需求。
是的,至少以我而言,我甚至在不少简单的场景下,觉得Deepseek V4 Flash都够了。
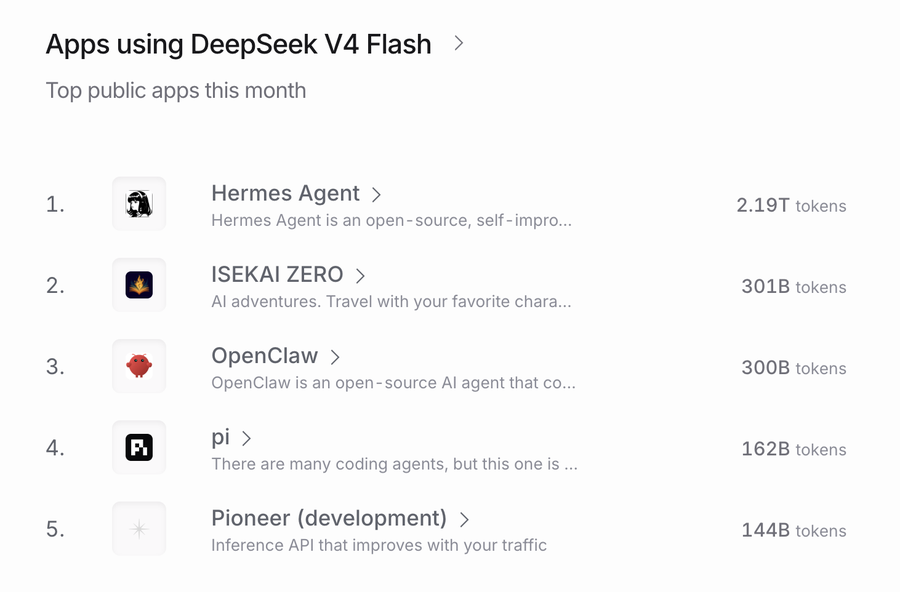
下图来自Openrouter,可以看到在这个以个人零售token消耗为主的市场上,Deepseek V4 Flash已经是消耗量排名第一的模型,日消耗3.72T token,排名第二的则是混元的Hy3 preview。
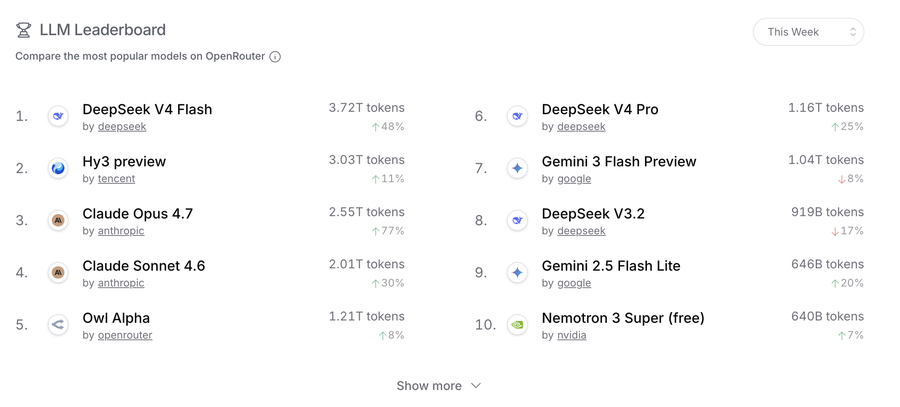
看Deepseek V4 Flash的五大消耗来源,Hermes、OpenClaw这样更强化聊天向的Agent在前三,夹在中间的ISEKAI ZERO更是一个AI娱乐应用。
毫无疑问,眼下最有付费意愿最肥美的大模型盈利模型,依然是Claude主打的面对B端企业的应用,在这块上,无论是Deepseek还是MiMO都仍有差距。
但别忘了,大模型每年都在快速迭代,往往新一代的Flash模型能够挑战上一代的Pro模型。
当二线模型,甚至二线模型的Flash版都能干大多数工作的时候,市场的需求,或许就会发生改变。
39元,5亿token。
半年前这还是一个荒谬的数字。半年后再回头看,未必是终点。
雪崩还在继续,虽然太多人或许还没意识到。而对于那些不需要最聪明、只需要够聪明的应用场景来说,春天已经到了。