最近,最值得警惕的,无疑是美股AI牛市的持续缩圈。
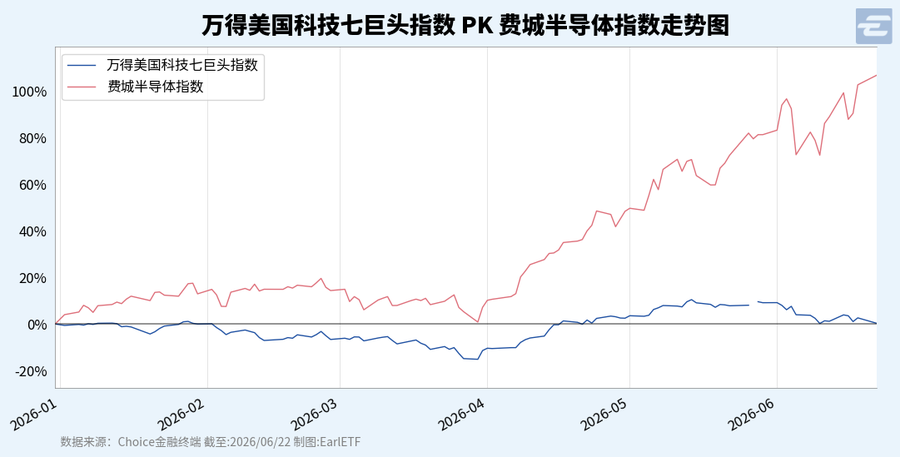
下图是万得七巨头指数与费城半导体指数今年迄今的走势对比,可以看到即使经历了4月以来的反弹,七巨头指数的今年迄今涨幅只剩下微乎其微的0.29%了,而且进入6月,是调整的趋势。反倒是费城半导体指数持续新高,今年迄今涨幅已经达到惊人的106.61%了。
这背后代表的一个风潮是,市场对于提供模型、提供数据中心的厂商们始终谨慎,转而向上游,去押注那些在北美算力Capex高涨下受惠的存储等厂商。
这一幕,对于经历过科网泡沫的人,多多少少会觉得有些熟悉。在科网泡沫后期,当市场对于一众乱七八糟的dot com股盈利产生怀疑时,就蜂拥杀入类似思科这样的“卖水者”板块,认为只要科网股继续烧钱,思科们就能继续受益。但残酷的历史就是,当科网股烧不起钱时,“卖水者”也会跟着一块陨落。
同样的隐忧,其实也存在于当下的AI浪潮。
对于昂贵大模型服务的需求,是否能持续下去?
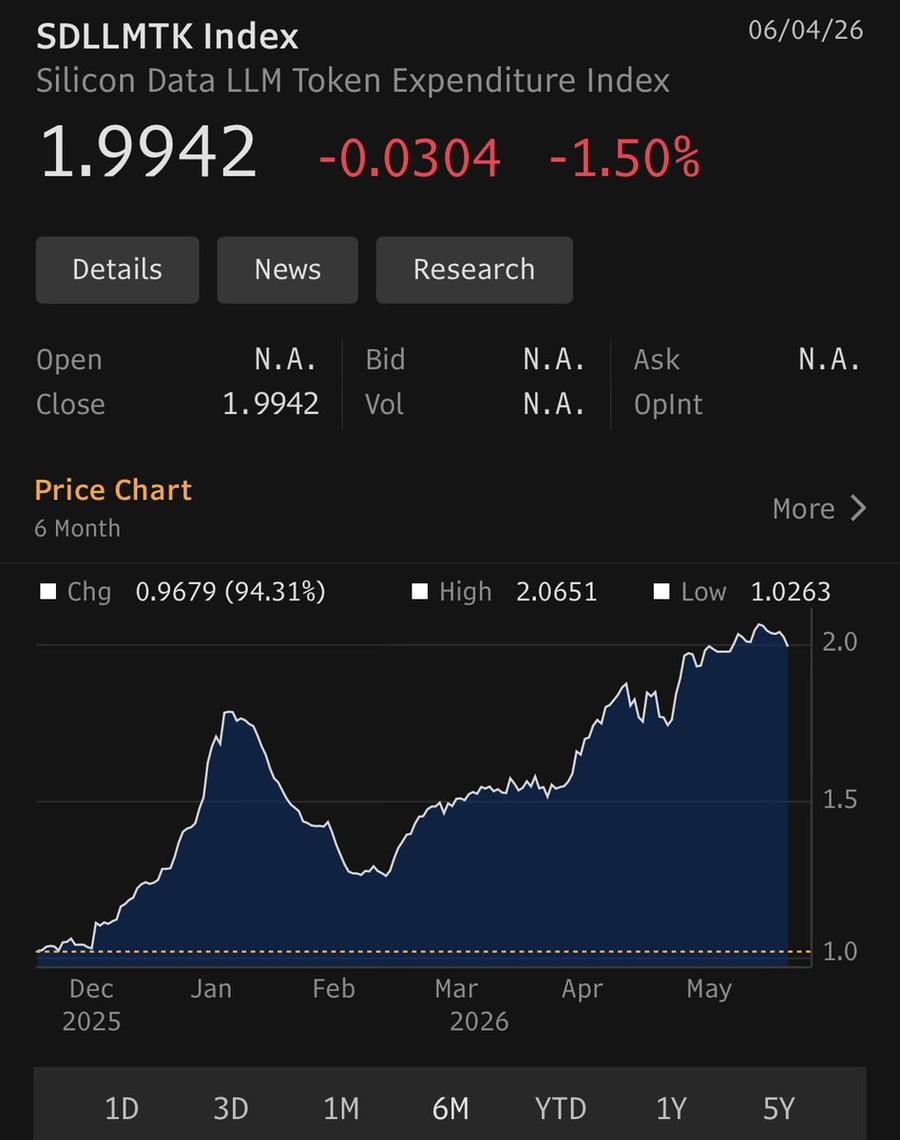
一个定量的指标,是SDLLMTK指数,这代表了美国的企业为了百万token愿意支付的单价。可以看到2月开始,出现了一波猛涨,这与Openclaw热火以及一堆大公司押注AI开发(以降本增效)的浪潮是一致的。但六月以来,这个指数是高位盘整并微跌的。似乎北美科技企业使用大模型的付费意愿,有所冷静。
此外,还有一个定性的信号值得关注。
之前有新闻说Uber去年末引入AI辅助编程,没想到AI编程的token预算在短短四个月内便已消耗殆尽。这个新闻的后续是五月底六月初,Uber为每位员工在每款AI智能体编程工具上设定每月1500美元的硬性Token支出上限,由于Uber内部使用Cursor和Claude两套体系,相当于单月3000美元的上限,全年3.6万美元,相比Uber工程师33万年薪中位数,大体是10%的占比。
这个数字,可比之前GPU厂商们鼓吹的,要给工程师配备与年薪等金额的token预算,实际多了。
其实这背后,是许多在2月份被“灌迷汤”的企业高管们想明白了,AI辅助是可以加快编码的速度,但一方面实践下来质量堪忧,还要大量人力去审核排错;另一方面也是最关键的,代码输出多了,不等于业务就能扩展,营收就能增加,如果营收不增加,成本增加,反而等于利润的减少。
其实这个问题,看看国内的短剧市场就明白了。Seedance 2.0的出现,的确大大加快了短剧的生产,但人们观看短剧的时长很难因此快速提升,整个短剧的大盘子(总营收)很难因为短剧生产效率的提升而迅速提升,再加上竞争加剧后可能需要花费更多的钱去抖音、红果上投流,最后的利润反而是下降的。
是的,AI模型的能力的确在快速提升,就像Claude Fable 5,用过的都知道比Claude Opus 4.8都还要强,这也是市场对于大模型的边界和上限不敢有任何轻视的原因。
但更强的模型,是否能转化成更强的营收,是一个问题。
平常刷小红书或者微信,能看到AI领域的KOL们对顶级模型,都是溢美之词,并用得不亦乐乎——但这核心是,他们作为个人用户,能买20美元或者200美元封顶的账户,并使用到实际价值数倍甚至更高的模型额度。
但真正的营收大头,也就是企业用户们,却是按照API接口的实际消耗付费,所以才会出现如Uber这样四个月干掉一年预算的失控。所以类似“模型路由”等思路也在涌现,也就是由Agent软件来判断一个任务的难易程度,并自动选择合适的模型,简单任务选简单模型,复杂任务选复杂模型。
而这,利好的是类似Deepseek V4 Pro、GLM 5.2、Qwen 3.7 Max、Kimi 2.7 Code这样编程口碑不错,性价比比较高的国产开源模型。
当然,模型使用的泡沫,短期恐怕不会破。
一个重要的事件就是两巨头的上市。根据最新的市场消息,Anthropic(Claude 的母公司)和 OpenAI 在五月底和六月初都提交了IPO上市申请。这两家之前的融资,估值都已经逼近万亿美元了,上市自然是希望估值再上一个台阶,顺带也募集足够多的弹药应对下一步AI的竞赛。
所以,在上市前,这两家恐怕会继续将市场最关心的ARR值(年度经常性收入)维护好。
最近在AI圈,许多人都在讨论OpenAI的“宽容”。普通包月会员帐号给的额度不但非常豪爽,而且对于“中转站”注册薅羊毛都不太打击,普遍被认为在上市前要冲一波ARR和token消耗量。但这样做的代价,就是利润率恐怕将更一塌糊涂。2026年一季度,OpenAI的非 GAAP(非美国通用会计准则)运营利润率为 -122%,即获得1美元营收,要亏损1.22美元。
至于Anthropic,最新的预测数据是2026年Q2将实现其历史上的**首次季度运营利润(Operating Profit)**转正,预计盈利5.59亿美元。究其原因,Claude模型以API的单价而不是包月卖给大公司,利润更丰厚。但也正因此,Anthropic的考验是能否稳住大企业的付费意愿,毕竟如Uber这样,不愿意做冤大头的企业越来越多。
这两家,为了上市,最近的业务模式,应该还会是粗放一点,面向估值运作。
模型使用的泡沫,短期不破,不等于不会放缓甚至阶段性消退。
但类似微软这样已上市企业,显然更实诚。微软家的GitHub Copilot,已经于6月1日开始调整计费模式,大幅消减对用户的补贴,从包月订阅模式改为类似API的基础额度+额外消耗单独计费模式;谷歌家的编程软件Antigravity其实转向更早,从去年末随便被用户薅羊毛,到现在非常抠门的额度计算。
当大模型的使用成本越来越敏感之后,一个经典的经济学问题就来了,这样的“变相涨价”,会否遏制需求,会否让token消耗的预期变小,会否让昂贵的最高档模型的需求部分甚至是大部分被低价模型取代,而这背后的问题都将影响算力巨头们Capex的意愿,而随后也会影响到从GPU到高端内存等上游的需求。
圈还在缩。
从七巨头缩到半导体,从半导体或许还会继续缩到少数几家。每一次缩圈,都伴随着一批“上一轮赢家”被甩出去。
牛市不会因为缩圈而立刻结束。但当圈小到只剩最后几个名字的时候,即使不是故事的终章,或许也是该阶段性闭目养神之时了。