GPT 5.6发布了,但大概率步Claude Fable 5的后尘,大部分普通人尤其是中国用户,短期用不到。
在有限模型可选的前提下,如何提升你的大模型输出上限?
大模型聚合网站OpenRouter倒是提出了一个有趣的思路——Funsion。
传统模型厂商,在提升自家模型输出上限上,更多是从思考预算、Harness之类上入手,OpenRouter因为是模型聚合网站,所以思路就会偏向于多模型整合——这恰恰是单一模型厂商的盲区,或者说不愿意尝试探索的领域。
OpenRouter的Fusion,最早是以聊天框的形式上线,你可以确定几个模型去思考,并选定一个模型将他们思考的结果综合后输出。
比如下面这个是我之前的尝试,用了三个廉价模型去翻译,然后交给Opus 4.6来综述。
翻译这个事儿,很难打分,评判模型产出好坏。
OpenRouter这次是引入DRACO测试集,这是Perplexity AI推出,包含 100 个深度研究任务,涵盖 10 个领域:学术研究、金融、法律、医学、技术、用户体验设计、常识、大海捞针式检索、个性化协助以及产品比较。
下面是OpenRouter公布的测试结果。标记Solo的就是单一模型的结果,Funsion的则是走上述多模型给答案高级模型综述(OpenRouter这次统一用了Opus 4.8)的结果。
当然,哪怕是Opus 4.8 + Opus 4.8 ,然后再用Opus 4.8 综述,也会有惊喜,相比单一Opus 4.8,分数能从58.8%提升到65.5%,已经赶超Claude Fable 5的65.3%了。这个结果其实不奇怪,大模型领域本来就有很多类似的“奇淫巧技”,比如一个问题复制粘贴两遍,会比只有一遍的提问获得更好的结果——这种不会发生在人类身上的智能呈现,在大模型上却是常态。
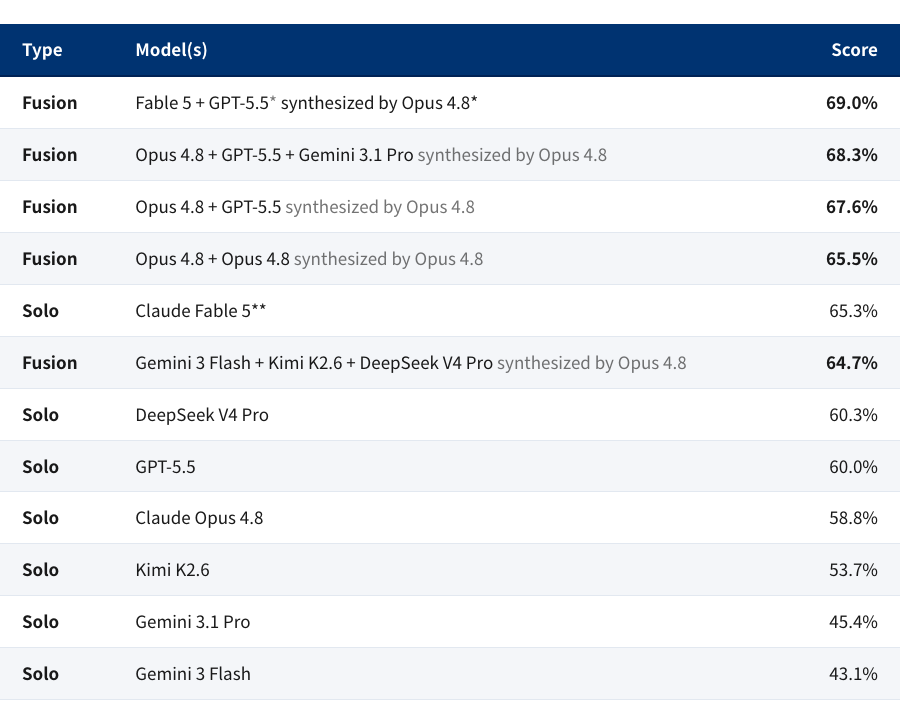
不过对于OpenRouter,或许这个测试最值得关注的是Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro 的组合,交由Opus 4.8综述后也有64.7%的得分,只是略微弱于Claude Fable 5。
站在2026年的6月,只谈模型的智能上限,不谈模型的成本,是不够的。
尤其是对于不能买月付会员,必须真金白银购买API的企业级用户。
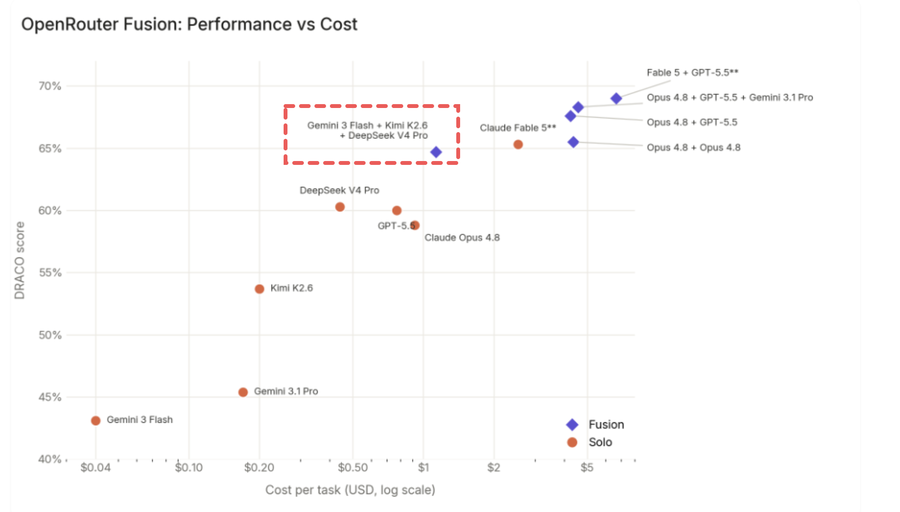
OpenRouter特地制作了一张成本与产出的散点图,请注意我用红色虚钱标记的部分,Gemini 3 Flash + Kimi K2.6 + DeepSeek V4 Pro的组合,在获得与Claude Fable 5相若的产出同时,成本只有一半。
对OpenRouter,做的是模型聚合的生意,所以他将这套原本只能用Chatbox的模式,做成了API接口,中间过程全部由OpenRouter完成,用户就像调用普通模型一样来调用,开发难度锐减。
当然,于我而言,更好奇的是,如果综述模型也改用国产低成本模型会如何?
毕竟在上面的测试排行中,DeepSeek V4 Pro单模型的成绩,竟然力压GPT 5.5和Claude Opus 4.8。以至于OpenRouter只能在问答部分,单独增加一个回答。

“三个臭皮匠,顶个诸葛亮”,这句传统老话,在大模型领域,似乎有了新的含义。
对于单一模型上限还有差异,但是性价比普遍比较高的国产开源模型而言,OpenRouter的这种探索,其实对于动摇海外顶级模型的性能优势,具有很大的挑战潜力。当然,上述结果只是基于DRACO测试集,还期待有更多的同类测试,尤其是在编程能力上的测试,能够陆续有来。